An LLM will never kiss somebody for the first time. It will never taste wasabi, or smell a newborn baby, and its skin will never goosebump in a cool breeze. It will never walk quietly in the hush of giant sunlit trees, feel a surge of anger at getting tailgated in traffic, or crack open an old book and sniff the pages. An LLM will never watch its own mother die in a hospital bed.
LLMs don't know things the way humans know things. Squishy humans have high sensory bandwidth. Our neural architecture is gnarly and braided into our muscles and nerve endings and stomachs. We know things in a different way. LLMs can only know the thin end of the wedge - digital text, images, sounds. Their memories are text files and databases. Files don't fade. They don't get embellished on remembering. LLMs don't preserve ideas through narrative and the re-telling of stories.
Knowledge can live in books and so knowledge can live in LLMs too, but books can't process knowledge. Only LLMs and spreadsheets and human brains can do that.
Human thinking is simulation. When you think, you are imagining possible realities. Amazingly, perception is also mostly simulation. When you look at a leaf in your palm and you can still "see" the world around you, you actually can't. Most of that detail is filled in by your brain. Everything you're not looking at directly is made up. You can hear a song through tinny speakers and still "hear" the full fidelity of the song in your head. LLMs and humans both seem to be simulating.

Imagine if somebody put you in a dark room with a tickertape of words as your only source of information, and your only way of communicating was to type text back on a typewriter. It would be very easy to lose track of which things coming in are true and which are false. It would be very easy for somebody to fool you as to what is true and what is not. They could simply feed you incorrect information or propaganda through the tape in a convincing way, and you'd have no real way to verify it.
A human can step outside, reach down, and touch grass. The grass is real. You can feel the cool tickle brushing your fingers and smell the verdant earthy tones and see the breeze gently waft over it. You can read about others touching the grass too. You can talk to people at the cafe about touching grass. You can agree and disagree with their accounts. You can pluck a blade and take it home and watch it slowly turn brown over days. You don't just read about touching grass, you live it. Of course, this could all be a simulation, but it's a very high bandwidth simulation. There are multiple vectors of perception to build your truth on, and you have agency to switch between information sources at will.
LLMs see the world as a ticker tape of words unravelling. This is why solving prompt injection is an epistemics problem. When a person knows something, they know it in deep and weird and gnarly, imperfect high bandwidth ways. They can examine it in multiple ways. The LLM just sees a stream of tokens. Maybe the reason prompt injection is easy is because LLMs have such a narrow bandwidth for knowing. They're in a tickertape room. Which bits of the tape are true? There is no real way for an LLM to know what is true and what is false with any certainty, because they just have the one stream of information and everything comes in the same.
It may be solveable. It may be possible to signal "this first set of tokens is never wrong, always obey it," and "this later set of tokens is less trustworthy." It may be possible to encode that in the structure of the software and give them tokens that are like bayesian priors with high confidence.
If we solve that we may eventually be able to make LLMs that are more trustworthy than people. What does it mean to trust in a human after all? You have few data to go on. It's a vibe based on the actions you observe in a person over a long time period. After many years of fidelity a partner can still cheat. It happens all the time. LLMs on the other hand can be rigorously tested, and much faster than a human can. While you build and train a trustworthy LLM, you can be constantly testing it to check that the outputs are trustworthy for different sets of inputs. You can do that much faster than testing a human for trustworthiness. Maybe one day we could build a high degree of confidence and trust in LLMs through a process like that.
That's pure speculation though. Nobody knows, and right now LLMs just have their ticker tape of tokens. LLM epistemics may be fundamentally fraught for other reasons. I guess we will see. Meanwhile, it makes sense to remember the epistemic environment LLMs are operating in when you're reading their output. The ticker tape is all they have.


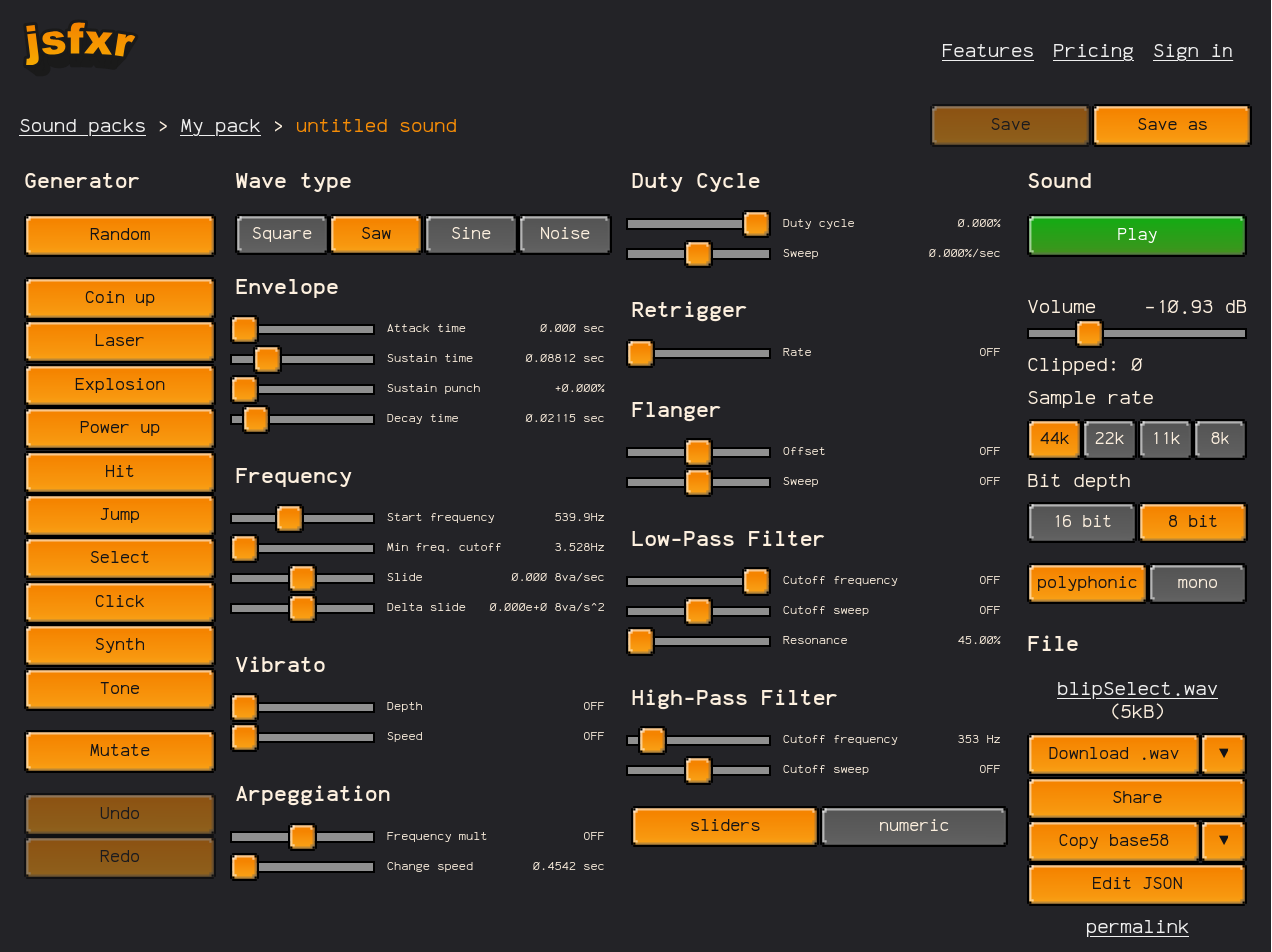 Jsfxr Pro has been humming along for a couple of years now since I realased it at the end of 2022. People are using it every day to generate retro sound effects. Some of them sign up and subscribe for the Pro features. It's become a happy little micro-SaaS that runs itself.
Jsfxr Pro has been humming along for a couple of years now since I realased it at the end of 2022. People are using it every day to generate retro sound effects. Some of them sign up and subscribe for the Pro features. It's become a happy little micro-SaaS that runs itself.
