

Aug. 31, 2018
A problem faced by decentralized systems is that of naming things. The problem is best expressed by Zooko's Triangle which conjectured that no single kind of naming system can provide names satisfying all three of the following properties:
- Human-meaningful: Meaningful and memorable (low-entropy) names are provided to the users.
- Secure: The amount of damage a malicious entity can inflict on the system should be as low as possible.
- Decentralized: Names correctly resolve to their respective entities without the use of a central authority or service.
Something as simple as a user handle or nickname becomes a complex issue in a decentralized system. What you ultimately want is something like a decentralized Twitter handle. The handle is a single human-memorable string which points to one and only one user in the system. The first user to register a particular name gets to claim that name. Obviously the case of Twitter handles is not decentralized as it requires the Twitter database as a single point of authority on who owns which name.
As the Wikipedia article points out, and Zooko has acknowledged, the invention of the Blockchain allows for solutions under certain conditions. However the effort required to design, build, and deploy a Blockchain along side your distributed application are quite steep. If you want to use an existing Blockchain implementation then either your users must be invested in it or your app must invest in it and pay for name registrations.
The former situation requires your users to not just install your app but also to acquire some particular Blockchain currency which steepens the barrier to entry for your app. The latter alternative requires your app to fork out for registrations which means the naming system of your decentralized app will fail if you or whichever entity is paying for the names shuts down.
The Keybase Method
In a decentralized system "one user" often means "one or more cryptographic key pairs". The site Keybase offers a good alternative naming system in the situation where "user" means "keypair". The solution is to use existing online identities held at different providers and link them cryptographically to the user's key(s). This means that third parties can verify an identity as follows:
@zooko on Twitter has public key B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7.
Or to put it more rigorously:
A person who has control of the private key corresponding to public key X also has write access to online service at Y.
A lot of the time when we want a name for something, the latter is what we actually want. We want to know that the existing relationship and trust I have for @zooko on Twitter can be carried over into this new decentralized system I have started using. If I have multiple existing relationships on different services with @zooko on Twitter then I can also verify those and in the decentralized app I can give @zooko the simple name "zooko" (which can often be inferred from usernames on services) and refer to the person with that handle from that point forward.
The way that Keybase does this is to help the user to sign a statement with their signing key saying "I am @name on service X" and then post the text and resulting signature on the service itself and keep a record of where somebody can find the post. If you do this it means you can prove to people that your signing key is associated with some existing internet identity such as your Twitter account. People who want to remain anonymous or pseudonymous with respect to their existing internet identities can simply skip this linking step.
This technique can actually be used to link any internet location that the user has write-access to back to a public key that they have the private key for. You simply sign a statement saying "I have write access to location X." and post it at "location X". Some examples:
- I have write access to https://mccormick.cx/ -> post signed message as textfile there.
- I have write access to https://twitter.com/mccrmx -> post signed message as tweet there.
- I have write access to https://github.com/chr15m -> post signed message as gist there.
Links to the signed post are kept and shared with other users who wish to verify the existing relationship.
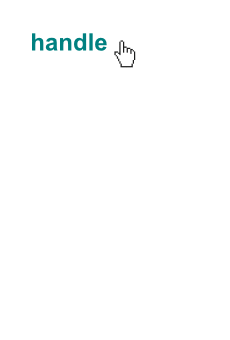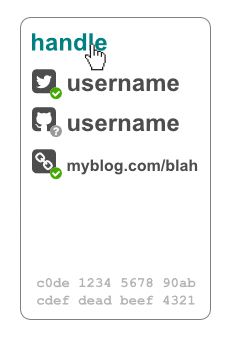
The decentralized "Keybase method"
Keybase is a centralized website and system which means that it has convenient integrations and is easy to use, but it relies on their infrastructure and centralized, proprietary software. The good news is it's possible to use the exact same technique that they use in a decentralized system. Doing this gives a user the power to make statements like:
@zooko on Twitter is me (B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7) on this decentralized service.
And then other people can confidently start using the name "zooko:twitter" in the place of B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7 in the decentralized system. In fact if the person has signed proof-of-write-access on multiple services and they have the same username on those services we might as well just start calling them "zooko" instead of "zooko:twitter+github". If two zooko's come along then we can just refer to them by their specific service-postfixed names, or some other qualifier, so that we can differentiate when interacting with them - see below for more on solving this "two Johns" problem.
What this means is that "zooko" in the decentralized system becomes a short-hand way of referring to an entity with whom we interact on a constellation of sites. In some ways this is more robust than naming systems on centralized systems (where anybody can "steal" a username by registering it before somebody else) because the alias actually represents the relationship rather than an entry in one specific proprietary database.
So how can we do the same thing in a decentralized system? Quite easily:
For each service the user is on:
- They sign a statement saying they have write-access to their account at that proprietary service with the signing key that they use on the decentralized service.
- They then post the signed statement to the proprietary service.
- When users are connected for the first time each user shares their links to "proof of linked identities" (if any) so that they can verify any existing Internet identities.
No-namers & the contacts list model
What about in the case where somebody does not sign anything to say that they own some existing online aliases? What if your Mum starts using decentralized service X and she does not have a GitHub or Twitter account? What if somebody chooses not to link their existing identities and instead decides to start afresh?
In the real world we don't really get to name ourselves. We can suggest a name to people, but they get to call us whatever they want. This is how nicknames happen and it's a bit of an aberration that in the online world we get to choose one canonical name by which people call us on proprietary services.
What if naming in online systems worked more like the decentralized real world? What if we suggested a name by which somebody could call us, but it was up to them to use it or to choose a different name by which to call us? What if, in this new decentralized service that my Mum has started using, I simply refer to her as "mum"?
If somebody has no existing online identities they can simply suggest a name when two users first connect and trade keypairs. The receiving party can then choose to adopt the suggested handle for that user, or if there is some conflict in their existing set of collected aliases, add a qualifier, or choose an entirely different name that makes sense to them.
This is the "contacts list" model of naming. You can tell me your name but I don't have to use it for your entry in my contacts list. I can adopt the name you've suggested but if I know two "Johns" then I'm likely to add some other qualifier like "Tennis John" and "Football John".
Aside: it would be funny if even DNS worked like this. The first time you loaded Google it would suggest to you "please call me google.com" but you could choose whatever name you wanted to type into the URL bar from that point forward. Norms would form between humans using the internet for what different sites would be called, and sometimes they would be called something different than what the person owning the domain wanted.
I don't think I would use "google.com" for example. I can think of some better names for that site.
Summary
The system proposed here for naming users in decentralized way uses an amalgam of two models: Keybase-style service signing, and the contacts list model.

To summarize the process of managing identities in this system:
- Each user in the decentralized app is identified by one or more cryptographic key pairs.
- A user may set a suggested handle they'd like other people to use.
- Optionally a user is able to add existing identities (Twitter, GitHub).
- Optionally the app helps the user create cryptographically signed back-links from their existing internet identities to the keypair.
- The app stores the user's links to their signed posts if any.
- When user A sees some user B for the first time the client receives the following information about user B:
- Their public key or fingerprint.
- Their suggested handle.
- URLs of their cryptographically signed identity-linking posts.
- The app then fetches user B's identity-link posts and verifies the signatures found there.
- Optionally user A is able to modify or supply their own local name (handle) for user B.
- The app creates a contact entry for user B with this information.
- When displaying user B the application uses the handle (chosen by user A) stored in the contact card.
- Under the hood the application uses user B's public key or cryptographic fingerprint/address to refer to that user.
- In the user interface the contact card is visible appropriately: for example on hover of user B's handle.
- The displayed card shows user B's handle, identity-links with verification status, and public key or fingerprint.
The raw public key or fingerprint(s) can additionally be used to verify real world identity out-of-band such as at key signing parties, personal meeting, or over a known secure channel.
Aug. 23, 2018








Recent-ish sketches. Been learning from The Etherington Brothers, Dr. Seuss, and How to Build Treehouses, Huts, and Forts.
Aug. 12, 2018

Web applications often follow a client-server model meaning that there is a piece of software which runs in your web browser (the client) and a piece of software which runs on a server somewhere. I'm interested in this model, where it came from, and where it's going, and I discuss this below. I'll also discuss a new model for self-hosting web applications that I've been exploring.
tl;dr
- To "self-host" a web application means to run the client and server on computers you own.
- Self-hosting is a basic foundation of decentralization.
- The "installable app" model on phones & PCs is quite decentralized.
- Decentralization is robust and anti-fragile.
- How can we bring self-hosting of web apps to everyone?
Brief history of software applications
In the old days most software people ran was in the form of applications that you would download onto your PC and run. This was quite a decentralised model in that you could find whatever software you liked and run it on your machine without asking permission from anybody.
The modern mobile-device app stores and the web have deviated from this model. In the case of app stores you can only download software that is sanctioned by the company who runs the app store. On Android it is quite easy to change the settings on your device to install software applications from any source but this is not the default, and on Apple devices it's very difficult to do.
The web has a more complicated approach. Running software in your web browser is generally as easy as visiting a URL and people are free to run whatever websites and "web apps" they like on their devices. As mentioned above however, the server-side portion of the web application you are using is often running on somebody else's server computer and not in your control.

Over time more and more functionality has moved from server side code into the web browser. Applications like Gmail pioneered this transition. Recent browser technologies like WebRTC and service workers have given a stronger base to build client-only applications on. The "add to homescreen" paradigm, whilst relatively obscure, presents a vector for running web applications on your computers and devices in a similar way to installed applications.
The buzz-word "serverless" captures the zeitgeist: moving more and more of the software off the server and into the web browser client. The reason software developers are generally in favour of this move is because it is easier to deploy code to web browsers than it is to deploy code to servers; it's easier to get users to run that software (just send them a link); and there is less of a maintenance burden if you don't have to keep a server running.
There's another strong reason why client side code is more favourable than server side code and that is because most server code is running on servers you don't own. For example when you run Gmail the server code and all of your emails are completely controlled by a third party and trusted third parties are security holes.
Even "serverless" in the context of web apps just means that the server component requires less infrastructure and is easier for developers to deploy. The code is still running on a machine owned by some third party who is neither the user or the developer.
Whilst this move towards client-side web applications is good in terms of user control, a problem even with "serverless" web applications that run in your browser is that the software can be modified without your consent. When you load up a web application tomorrow the developer might have made a new version with features you don't like and your browser will load the new version automatically even if you wanted the old version. Even worse, because you load a fresh copy of the software each time you use it, a man-in-the-middle attacker might sneak a malicious bit of code into the version you load tomorrow that is not there today.
There are also many use-cases where only a piece of server-side software will do. Generally these use-cases fall under the umbrella of asynchronous communication, such as storing a file for later retrieval, sending a message to one or more people which might only be received when you are offline, syncing state between devices which might be connected at different times etc.
Examples of things the server code will typically take care of:
- Connecting client apps together in real-time.
- Data manipulation functions.
- Proxying network requests.
- Persistent data storage.
- Running periodic jobs.
- Access control.
So the world is trending towards a more fragile situation of centralized control of the software we all rely on. It would be better for humanity if we were instead moving towards decentralized models of software where an individual can run and control the software they want without fear of a fragile centralized system failing or being used against them by powerful interests and hackers.

Self-hosting
So these latter problems are some of the reasons why self-hosting web applications is still a good move in terms of security and control. When self-hosting, all of the software and all of the data is running on your own computers and you don't have to trust any third party to not be evil, corrupt, make mistakes etc. You can choose which software to install and run and when without obstruction. You get the benefits of cloud connected software - shared state between devices and other users - without having to trust a third party.
The main problem with the self-hosting approach is that it is very technical and therefore simply not an option for most users. Some of the barriers to people self-hosting their web software stacks:
- Renting or building a server.
- Installation of server side code.
- SSL certificate management.
- Server maintenance.
- Access control management.
- Securing the server.
These are the types of things that systems administrators are paid a lot of money to take care of because they are difficult and skillful work. These are the things that big companies are doing for you when you use their online services. The unwritten contract we engage in today is that we give big companies control over our digital life and our valuable personal data in exchange for their building, installing, and maintaining the infrastructure code on their servers.
An additional problem is that even in the "host your own server" model there is a lot of centralization and passing around of valuable and private personal information. For example obtaining a domain name and SSL certificate requires central authorities who almost always require a lot of personal information. Not to mention forking over cash. Additionally, even if you host your code on a VPS - as is the case with almost all server side code on the internet - then some trusted 3rd party has unlimited access to the machine you are renting.

Some existing proposed solutions
So the interesting question is whether there is some way to make self-hosting possible for everybody in the same way that PCs and phones made "run the software I want" easy for everybody.
There was a time when a lot of web applications were deployed as simple PHP scripts with HTML, CSS & Javascript for the front-end. This was probably the simplest format for self-hosted applications as it was easy to find hosting providers who would let you run PHP, and installation was as simple as copying files up to a server. I think this is a big reason why PHP has remained popular for so long despite the fact that it's such an awful language with frequent security issues. It simply let you do what you want. These days though, a lot of modern software on the internet is not written in PHP and developers often prefer other langauge ecosystems.
Another idea for self-hosting was the Freedom Box pioneered by Free Software enthusiasts in the 2000s. The idea is pretty good but does not seem to have acheived widespread adoption. My guess is the use cases are still too obscure for most users. what does "run your own XMPP server" mean? Most people have no idea.
A lot of people today are of the mind that "blockchain" is the singular solution to the issue of decentralizing the software we run. In this model you pay in small increments for the server side code which runs on a distributed system shared amongst many participants. You maintain control of your piece of the distributed service and your data stored in it using cryptography. In this model the server component and app state is shared across many computers all at once and you basically pay for a small slice of it.
This is a fascinating idea but I am not completely convinced that "blockchain" will be the future of decentralized software applications because:
- So far it is unproven in all except one application, that of decentralized digital gold.
- There are a number of very successful decentralized systems that function well without any kind of token/monetary incentive (email, irc, http, bittorrent, git etc.) and that original model of decentralization by cooperating parties is still a sound, well proven one. People still use email.
- The blockchain design encapsulates a trade-off of low efficiency for immense security and trust minimization. This means that blockchains are very good at storing and securing transaction data but they are not very efficient at storing lots of other types of data. Imagine having your own dropbox folders also filled with encrypted copies of those of everybody else in the world. It does not scale.
In addition to the above ideas there exist new ecosystems like ownCloud and Sandstorm which enable people to deploy their own "stacks" hosted on their own servers. These are noble efforts at decentralization and self-hosting into which many people have poured a lot of work. The problem with these "host-it-yourself cloud stacks" is that they often still require trust in some 3rd party hosting service, and quite deep technical knowledge. Sure, to a nerd it is easy to upload a PHP script and configure a MySQL server, purchase VPS hosting, install a Let's Encrypt SSL certificate, but it is not always so easy to a nerd's mother, father or friend.

A simple platform for self-hosting
I've been thinking about all of this in recent years. I've been asking myself these questions:
What if running persistent server side code was available to anybody, even non-technical users? What if installing server side software was as click-tap easy as it is on a phone or PC? What if you could run cloud software and servers on the desktop PC in your office, or tablet, or Raspberry Pi on your home network? What does it look like when anybody in the world can self-host their "cloud" software?
Criteria for such a system would be:
- Easy to set up and administer.
- Easy to install and uninstall new services.
- Interfaces easily with web browser client software.
- Secure.
- Completely user-controlled and decentralized.
As I've thought about these ideas I've also been tinkering with WebTorrent. It's a cool piece of technology which is bringing a chunk of the BitTorrent architecture to the web.
Working with this technology made me realise something the other day: it's now possible to host back-end services, or "servers" inside browser tabs.

Instead of a VPS server running in some data center, you have a browser tab running on a spare computer. Instead of clients talking to servers over HTTP they can talk over WebRTC. You build your "backend" service code with the same tech as your client side web app, with HTML and Javascript.
When I realised this it blew my mind. I couldn't stop thinking about it. Maybe the persistent browser tab on the home PC can be the new server for self-hosting users? What if grandma could build out a server as easily as opening a browser tab and leaving it running?
So anyway, I've made this weird thing to enable developers to build "backend" services which run in browser tabs. It's called Bugout and it has been fun to hack together.
![]()
Check it out and let me know what you think.