Watch Later is a 100% client-side web app you can use to save a list of YouTube videos without logging into YouTube itself. It syncs across devices using the Nostr protocol and relays, making it fairly decentralized.
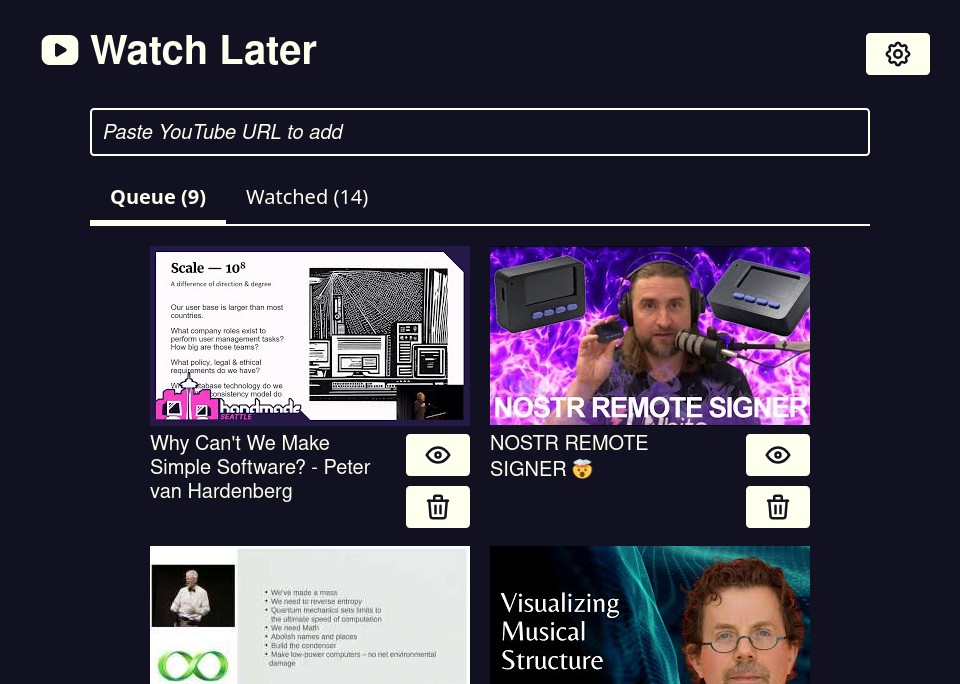
You can find the app at mccormick.cx/apps/watch-later. Because it's a 100% client-side web app, you can self-host it on any static web hosting provider. You can get the source code on my GitHub at chr15m/watch-later, and you can download a zip file of the app too.
How to Use It
To add a video, simply paste the URL into the input at the top. The video will be added to your watch list. Click on any video to watch it, and the playback position will be saved as you watch so you can resume again later from the same place. You can also mark videos as watched and they'll go into the watched tab, and you can delete videos from your list permanently.
Cross-Device Sync
You can sync your watch list and video playback positions easily across devices without logging in. The data is encrypted and synced using the Nostr protocol on public Nostr relays. The sync works across different devices by sharing the Nostr key or nsec.
To get the key, go to the settings page by clicking on the cog in the top right hand corner. Then you can use the copy button to copy the key. You can optionally encrypt the key with a password for extra safety. Once you've copied the key, you can transfer it to your other device and paste it in on the settings page. That will immediately sync your video list across as well as any playback positions.
The Technology
Watch Later is about 800 lines of code written in ClojureScript. It syncs your video list across multiple devices without any backend code, and that means it can be hosted on static web hosting. It was super fun building this on the Nostr protocol and not needing to build or maintain any server infrastructure or accounts or anything like that. The sync seems to be fast and reliable, and I haven't had any issues so far.
Deployment is fun because I can just use a tiny bash script to rsync the front-end files up to my static web server. That's much simpler and less error-prone than deploying a full service with a backend. I also like that people can use the app without logging in. I don't have to collect any personal data to enable the network features.
So that's Watch Later. I hope the app's useful to you, and I can highly recommend building stuff on the Nostr protocol. Enjoy!