This is the pattern I use for mastering algorithmic electronic music that I write.

First, each audio source or channel Sn is given a random (sometimes hand tuned) delay of 0 to 20 milliseconds on either the left or right channel in RPn. My friend Crispin put me on to this technique, which gives each audio source its own psycho-acoustic space in the mix, probably due to the Haas effect.
Next the resulting sources are summed together - separately for left and right channel. Here you can also run the combined signal through a high pass filter set at 5Hz to remove any DC offset present in the signal.
Then the combined signal is passed through a reverb with mostly "dry" signal - maximum 30% wet as a general rule of thumb. Adjust the reverb to taste. I'll usually make it a bit long and airy but subtle.
Next we win the loudness wars. This is dance music and we want people to dance, so it has to sound powerful. To acheive this we do something horrible: measure the RMS - the power of the sound - and then amplify until the power of the signal is normalised. Here is the "auto compress" Pure Data patch I use for doing this:
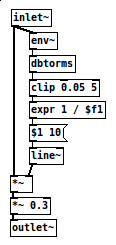
The env~ object here is a simple envelope follower and the source code is here. The dbtorms function source code is here. The possible magnitude of the power correction is limited by the clip function which does what it says on the box, and the resulting multiplier is smoothed with a 10ms rise and fall time (line~) to get rid of sudden discontinuities. Only 30% of the resulting power-normalized signal is mixed with the original signal.
Finally, run the mixed signal through a soft-clipper before sending it to the speakers. Soft clipping is a good idea because the power normalisation step above will push the peaks up above 1.0 and we don't want harsh hard-clipped distortion to be audible.
The soft clipper I use (probably incorrectly called "sigmoid" in the diagram) is simultaneously a compressor to get that extra punchy sound:
2 / (1 + pow(27.1828, -$v1)) - 1
Where $v1 here corresponds to your vector of incoming audio samples.
Hopefully this method doesn't break any international treaties or anything.
Enjoy!