A problem faced by decentralized systems is that of naming things. The problem is best expressed by Zooko's Triangle which conjectured that no single kind of naming system can provide names satisfying all three of the following properties:
- Human-meaningful: Meaningful and memorable (low-entropy) names are provided to the users.
- Secure: The amount of damage a malicious entity can inflict on the system should be as low as possible.
- Decentralized: Names correctly resolve to their respective entities without the use of a central authority or service.
Something as simple as a user handle or nickname becomes a complex issue in a decentralized system. What you ultimately want is something like a decentralized Twitter handle. The handle is a single human-memorable string which points to one and only one user in the system. The first user to register a particular name gets to claim that name. Obviously the case of Twitter handles is not decentralized as it requires the Twitter database as a single point of authority on who owns which name.
As the Wikipedia article points out, and Zooko has acknowledged, the invention of the Blockchain allows for solutions under certain conditions. However the effort required to design, build, and deploy a Blockchain along side your distributed application are quite steep. If you want to use an existing Blockchain implementation then either your users must be invested in it or your app must invest in it and pay for name registrations.
The former situation requires your users to not just install your app but also to acquire some particular Blockchain currency which steepens the barrier to entry for your app. The latter alternative requires your app to fork out for registrations which means the naming system of your decentralized app will fail if you or whichever entity is paying for the names shuts down.
The Keybase Method
In a decentralized system "one user" often means "one or more cryptographic key pairs". The site Keybase offers a good alternative naming system in the situation where "user" means "keypair". The solution is to use existing online identities held at different providers and link them cryptographically to the user's key(s). This means that third parties can verify an identity as follows:
@zooko on Twitter has public key B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7.
Or to put it more rigorously:
A person who has control of the private key corresponding to public key X also has write access to online service at Y.
A lot of the time when we want a name for something, the latter is what we actually want. We want to know that the existing relationship and trust I have for @zooko on Twitter can be carried over into this new decentralized system I have started using. If I have multiple existing relationships on different services with @zooko on Twitter then I can also verify those and in the decentralized app I can give @zooko the simple name "zooko" (which can often be inferred from usernames on services) and refer to the person with that handle from that point forward.
The way that Keybase does this is to help the user to sign a statement with their signing key saying "I am @name on service X" and then post the text and resulting signature on the service itself and keep a record of where somebody can find the post. If you do this it means you can prove to people that your signing key is associated with some existing internet identity such as your Twitter account. People who want to remain anonymous or pseudonymous with respect to their existing internet identities can simply skip this linking step.
This technique can actually be used to link any internet location that the user has write-access to back to a public key that they have the private key for. You simply sign a statement saying "I have write access to location X." and post it at "location X". Some examples:
- I have write access to https://mccormick.cx/ -> post signed message as textfile there.
- I have write access to https://twitter.com/mccrmx -> post signed message as tweet there.
- I have write access to https://github.com/chr15m -> post signed message as gist there.
Links to the signed post are kept and shared with other users who wish to verify the existing relationship.
The decentralized "Keybase method"
Keybase is a centralized website and system which means that it has convenient integrations and is easy to use, but it relies on their infrastructure and centralized, proprietary software. The good news is it's possible to use the exact same technique that they use in a decentralized system. Doing this gives a user the power to make statements like:
@zooko on Twitter is me (B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7) on this decentralized service.
And then other people can confidently start using the name "zooko:twitter" in the place of B123h9EAgVdnXWjxUa3N9Amg1nmMeG2u7 in the decentralized system. In fact if the person has signed proof-of-write-access on multiple services and they have the same username on those services we might as well just start calling them "zooko" instead of "zooko:twitter+github". If two zooko's come along then we can just refer to them by their specific service-postfixed names, or some other qualifier, so that we can differentiate when interacting with them - see below for more on solving this "two Johns" problem.
What this means is that "zooko" in the decentralized system becomes a short-hand way of referring to an entity with whom we interact on a constellation of sites. In some ways this is more robust than naming systems on centralized systems (where anybody can "steal" a username by registering it before somebody else) because the alias actually represents the relationship rather than an entry in one specific proprietary database.
So how can we do the same thing in a decentralized system? Quite easily:
For each service the user is on:
- They sign a statement saying they have write-access to their account at that proprietary service with the signing key that they use on the decentralized service.
- They then post the signed statement to the proprietary service.
- When users are connected for the first time each user shares their links to "proof of linked identities" (if any) so that they can verify any existing Internet identities.
No-namers & the contacts list model
What about in the case where somebody does not sign anything to say that they own some existing online aliases? What if your Mum starts using decentralized service X and she does not have a GitHub or Twitter account? What if somebody chooses not to link their existing identities and instead decides to start afresh?
In the real world we don't really get to name ourselves. We can suggest a name to people, but they get to call us whatever they want. This is how nicknames happen and it's a bit of an aberration that in the online world we get to choose one canonical name by which people call us on proprietary services.
What if naming in online systems worked more like the decentralized real world? What if we suggested a name by which somebody could call us, but it was up to them to use it or to choose a different name by which to call us? What if, in this new decentralized service that my Mum has started using, I simply refer to her as "mum"?
If somebody has no existing online identities they can simply suggest a name when two users first connect and trade keypairs. The receiving party can then choose to adopt the suggested handle for that user, or if there is some conflict in their existing set of collected aliases, add a qualifier, or choose an entirely different name that makes sense to them.
This is the "contacts list" model of naming. You can tell me your name but I don't have to use it for your entry in my contacts list. I can adopt the name you've suggested but if I know two "Johns" then I'm likely to add some other qualifier like "Tennis John" and "Football John".
Aside: it would be funny if even DNS worked like this. The first time you loaded Google it would suggest to you "please call me google.com" but you could choose whatever name you wanted to type into the URL bar from that point forward. Norms would form between humans using the internet for what different sites would be called, and sometimes they would be called something different than what the person owning the domain wanted.
I don't think I would use "google.com" for example. I can think of some better names for that site.
Summary
The system proposed here for naming users in decentralized way uses an amalgam of two models: Keybase-style service signing, and the contacts list model.

To summarize the process of managing identities in this system:
- Each user in the decentralized app is identified by one or more cryptographic key pairs.
- A user may set a suggested handle they'd like other people to use.
- Optionally a user is able to add existing identities (Twitter, GitHub).
- Optionally the app helps the user create cryptographically signed back-links from their existing internet identities to the keypair.
- The app stores the user's links to their signed posts if any.
- When user A sees some user B for the first time the client receives the following information about user B:
- Their public key or fingerprint.
- Their suggested handle.
- URLs of their cryptographically signed identity-linking posts.
- The app then fetches user B's identity-link posts and verifies the signatures found there.
- Optionally user A is able to modify or supply their own local name (handle) for user B.
- The app creates a contact entry for user B with this information.
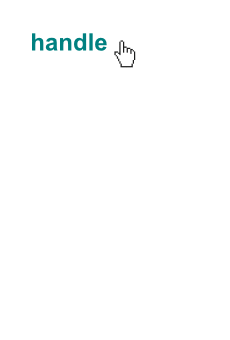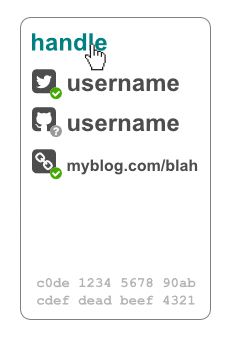
- When displaying user B the application uses the handle (chosen by user A) stored in the contact card.
- Under the hood the application uses user B's public key or cryptographic fingerprint/address to refer to that user.
- In the user interface the contact card is visible appropriately: for example on hover of user B's handle.
- The displayed card shows user B's handle, identity-links with verification status, and public key or fingerprint.
The raw public key or fingerprint(s) can additionally be used to verify real world identity out-of-band such as at key signing parties, personal meeting, or over a known secure channel.